A misspelled Disallow or misplaced User-agent line in a robots.txt file can silently block search engines from crawling critical pages. Learning how to generate robots.txt files spellmistake-free is essential for anyone managing a website’s search visibility. Readers exploring generate robots.txt files spellmistake will also find context in Droven.io USA Tech Market Updates: Key Developments and Analysis
The robots.txt file sits in a website’s root directory and tells search engine crawlers which pages or directories they can or cannot access. It follows the Robots Exclusion Protocol, a standard adopted by major search engines including Google and Bing. Even a small typographical error — such as writing “Disalow” instead of “Disallow” — can cause the entire directive to be ignored, potentially exposing private content or blocking access to important pages. Background on generate robots.wikipedia.org/wiki/Perplexity_AI” rel=”noopener noreferrer” target=”_blank”>Perplexity AI
Common Mistakes That Break a Robots.txt File
Several recurring errors undermine robots.txt effectiveness. The most frequent is misspelling directives: “Useragent” instead of “User-agent,” or “Dissalow” instead of “Disallow.” These cause crawlers to skip the rule entirely. Another common issue is incorrect path formatting. A rule reading “Disallow: /private” blocks only URLs beginning with /private, while “Disallow: /private/” is more specific. Omitting the trailing slash or adding an extra one changes the scope of the directive.
Structural mistakes also cause problems. Placing a User-agent line inside a block belonging to a different agent, or forgetting to separate rules with a new line, can invalidate sections of the file. Google’s robots.txt parser is somewhat forgiving, but Bing and other engines may reject malformed files outright. According to Google’s official Search Central documentation, unknown directives are ignored, which means a misspelled command simply has no effect — the very outcome site owners want to avoid. Background on generate robots.com/generate-robots-txt-files-spellmistake/” rel=”noopener noreferrer nofollow” target=”_blank”>Generate Robots.txt Files SpellMistake: Fix Errors & Improve Crawling
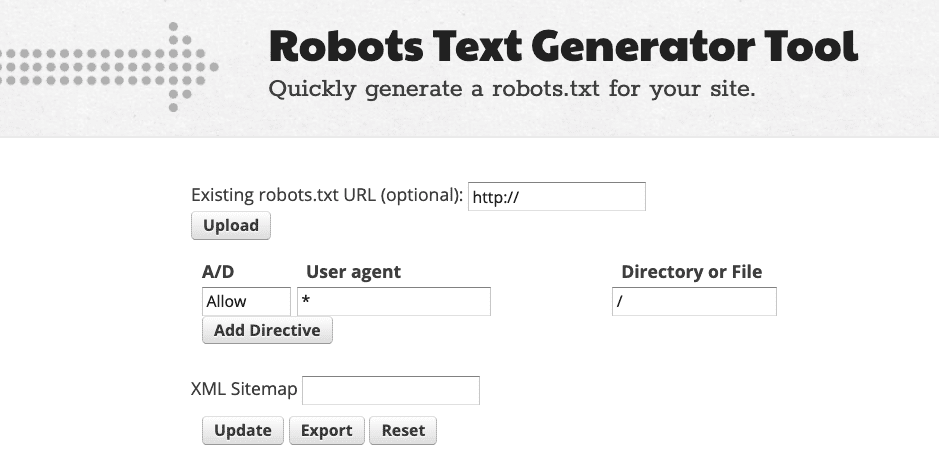
How to Generate Robots.txt Files Spellmistake-Free Using Tools
Online robots.txt generators reduce human error by providing structured interfaces where users select options rather than typing raw text. Tools such as those offered by Google Search Console, Small SEO Tools, and RobotsTxt.org let users build rules through dropdown menus and checkboxes. This approach virtually eliminates the risk of misspelling a directive because the tool outputs the correct syntax automatically.
Many content management systems also include built-in robots.txt editing features. WordPress, for instance, generates a virtual robots.txt file based on settings found under “Settings > Reading.” Plugins like Yoast SEO and Rank Math add graphical interfaces for managing crawl directives without touching code. For developers working with frameworks like Next.js or Django, template-based generators can produce validated robots.txt files as part of the build pipeline, catching syntax errors before deployment.
Validation tools serve as a final safety net. Google Search Console includes a robots.txt Tester that simulates how Googlebot interprets a file, flagging syntax issues and showing which URLs would be blocked or allowed. Running a generated file through this tool before publishing catches problems that a visual review might miss.
What Is Confirmed and What Remains Unverified About Robots.txt Best Practices
Google’s Search Central team has publicly stated that unknown directives in robots.txt are ignored rather than treated as errors.
What remains less clear is how consistently smaller or regional search engines handle edge cases. Some crawlers may interpret ambiguous syntax differently, and there is no universal enforcement mechanism beyond voluntary compliance. The interaction between robots.txt rules and meta robots tags can also create confusion: a page blocked by robots.txt may still appear in search results if another page links to it and passes along a snippet, because the crawler never fetched the blocked page’s meta tags.
Why Getting Robots.txt Right Matters for Search Visibility
A correctly configured robots.txt file is one of the simplest yet most impactful technical SEO elements. It prevents search engines from wasting crawl budget on duplicate or low-value pages, such as admin panels or internal search result pages. This ensures that important content gets indexed faster. For large e-commerce sites with thousands of faceted navigation URLs, a well-structured robots.txt can mean the difference between comprehensive indexing and significant gaps in search presence.
Beyond SEO, robots.txt plays a role in security posture by keeping sensitive directories out of public crawl data. While it is not a security measure on its own — the file is publicly readable — it reduces the likelihood that private URLs surface in search engine caches. As search engines continue to expand into AI-driven summarization and indexing, the precision of crawl directives only grows in importance.
Frequently Asked Questions
What happens if I misspell a directive in robots.txt?
Search engines that follow the Robots Exclusion Protocol simply ignore unrecognized directives. A misspelled word like “Disalow” is treated as unknown, so the intended rule has no effect. This means the URLs you meant to block could be crawled freely, or the pages you wanted open might remain unrestricted.
Can I validate my robots.txt file for free?
Yes, Google Search Console offers a free robots.txt Tester tool that checks syntax and simulates how Googlebot interprets the file. Several third-party websites also provide free validation services that flag common errors such as misspelled directives, incorrect formatting, and structural issues.
Does robots.txt work the same way on all search engines?
Major engines like Google, Bing, and Yahoo follow the same core Robots Exclusion Protocol. However, handling of edge cases and non-standard directives can vary. Some smaller or regional crawlers may interpret ambiguous syntax differently, so testing across multiple platforms is advisable for high-stakes configurations.
How often should I update my robots.txt file?
There is no fixed schedule, but the file should be reviewed whenever the site structure changes significantly — such as during a redesign, migration, or the addition of new sections. Regular audits, at least quarterly, help catch outdated rules that may block newly important content or allow crawling of pages that should be restricted.
Is robots.txt a security measure for my website?
No, robots.txt is not a security tool. The file is publicly accessible, and anyone can read its contents. It is a request to crawlers, not an enforcement mechanism. Sensitive content should be protected with proper authentication and access controls rather than relying on robots.txt directives alone.